AI Struggles to Deliver Real Value
Existing data foundations lack the meaning, context and controls AI needs to deliver reliable business value.
Missing Financial Meaning
Schemas and field names describe how data is stored, but rarely capture financial concepts, relationships or business rules. Without machine-readable semantics, AI can generate convincing outputs that are incomplete, irrelevant or wrong.
Fragmented and Hidden Data
Important data is scattered across operational systems, warehouses, documents, catalogues and individual teams. AI cannot reliably determine what data exists, where to find it or how different sources relate.
Limited Trust and Traceability
Financial institutions need more than an answer. Every AI output must carry an evidence path—the source data, lineage, transformations and rules behind it—so results can be traced, audited and shown to be permitted for the intended use.
No Practical Path to Implementation
Many AI initiatives produce promising demonstrations but struggle to become useful capabilities embedded in real business processes. Without a practical framework connecting data, meaning, evidence and controls, progress remains slow and difficult to scale.
The Finsight Solution
Finsight helps financial institutions build the semantic, technical and control foundations their data needs to support reliable AI.
Financial Semantic Foundation
Industry-aligned financial ontologies, canonical concepts and semantic models provide a starting foundation, extended with your institution's own terminology, data definitions and business rules.
Modular Runtime Accelerators
Reusable components for semantic search, graph context, evidence, lineage, workflow orchestration and AI integration accelerate implementation.
Finsight provides the common foundation so your teams can focus on the business logic that is specific to your organisation.
AI Control and Assurance
A loosely coupled governance and runtime-control framework covering policy, permissions, evidence, validation, monitoring, traceability and human oversight.
It is designed around applicable regulatory, risk and governance requirements, while remaining adaptable to your organisation's own control framework.
Data Estate Assessment and Blueprint
Finsight investigates your existing systems, datasets, schemas, pipelines, lineage and governance capabilities to identify what already exists, what is missing and what should be built next.
The outcome is a focused implementation blueprint grounded in your real data estate—not a generic transformation plan.
The Finsight AI-Foundry Architecture Behind Our Delivery
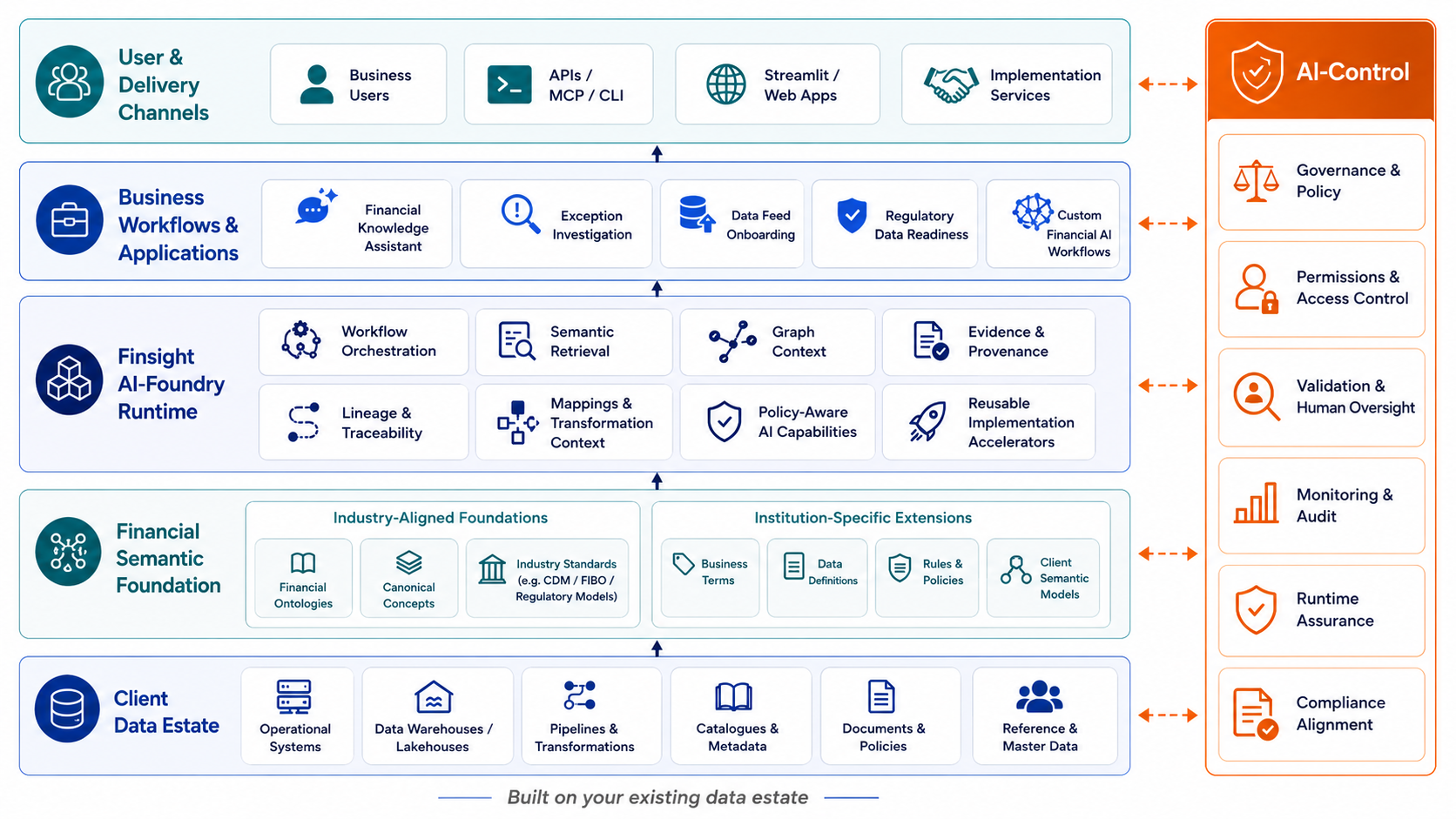
Our Approach
Finsight combines a broad financial data-foundation framework with focused, measurable implementation for tangible business cases—no buzzwords, minimal slideware, and progress you can verify in working systems.
Business-Case Led
Every engagement starts with a specific process, decision or use case that can create measurable value.
The broader AI-Foundry framework provides architectural direction, while implementation remains deliberately narrow and practical.
Simple, Substance-Led Delivery
We avoid unnecessary buzzwords, excessive ceremonies and presentation-heavy processes.
The work is grounded in real systems, schemas, data, controls and business decisions. Documentation supports delivery—it does not replace it.
Focused and Senior-Led
Finsight does not bring large delivery teams or layers of project management.
You work directly with senior expertise to clarify the problem, establish the direction, define the architecture and build the core semantic and control foundations.
Designed Around Your Business
Every institution has its own systems, terminology, data structures, controls and operating model. Generic off-the-shelf products rarely fit these realities without significant adaptation.
Finsight combines reusable foundations with institution-specific architecture, semantics and business logic.
The services we offer
We are a specialist, founder-led firm—focused, flexible and intentionally lean, with senior expertise involved throughout every engagement.
Data Foundation Assessment
Investigate your existing systems, datasets, models, lineage, controls and priority use cases.
Identify what already exists, where the critical gaps are and what should be built next.
Financial Semantic Foundation
Define the financial concepts, ontologies, canonical models, mappings and business rules required for your organisation.
Connect industry-aligned foundations with your institution-specific terminology and data estate.
Governed Use-Case Implementation
Start with a focused business use case and build the semantic, data, evidence and control capabilities needed to support it.
Use Finsight accelerators to move quickly from problem definition to a working, governed implementation.
Specialist Advisory & Problem Solving
Access senior financial data and architecture expertise when you need independent advice, rapid investigation or practical direction.
Support can cover architecture reviews, difficult data issues, semantic modelling, design decisions, delivery blockers and targeted technical guidance.